OpenClaw [转] 不要再折腾复杂门槛高的记忆系统了
一、AI Agent 记忆系统的困境

- 多个 Agent 无法共享记忆(每个都要重新学习你的习惯)
- 跨设备无法同步(笔记本和服务器是两个世界)
- 跨框架无法迁移(OpenClaw 的记忆,Claude Code 读不到)
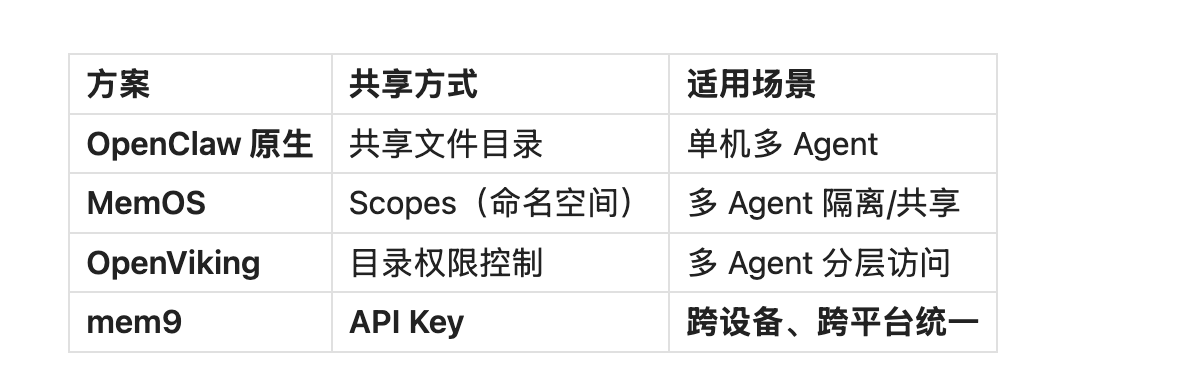
二、现状分析:以 OpenClaw 原生记忆为例


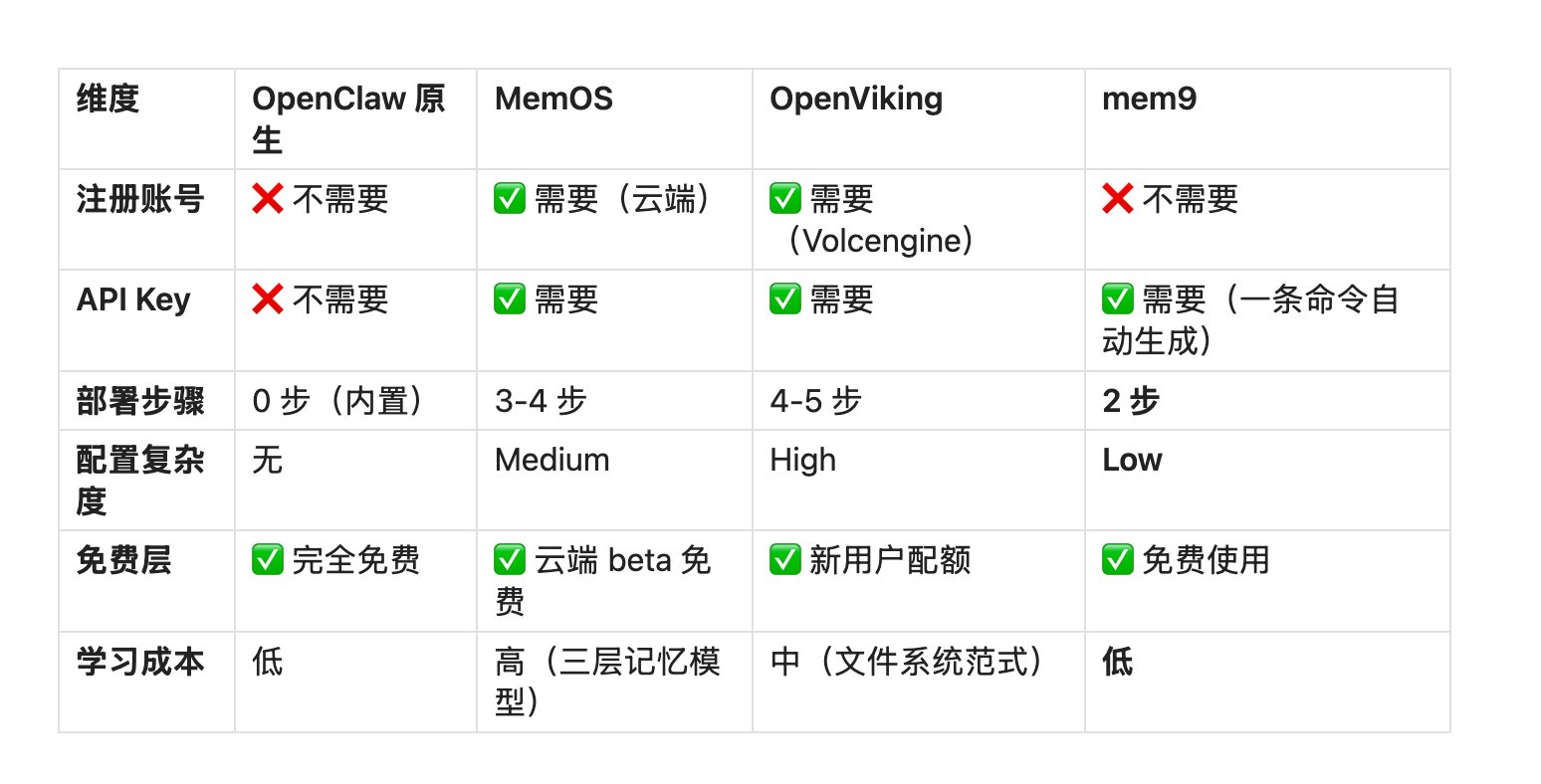
- ✅ 开箱即用,0 配置(hook 自动通过 skill 注入非常好用!)
- ✅ 纯文本存储,易于理解和调试
- ✅ 完全本地,无隐私担忧
- ❌ 本地存储:换台电脑就失效
- ❌ 单机限制:无法跨设备同步
- ❌ 框架绑定:只能在 OpenClaw 内使用
- ❌ 无结构化:难以支持复杂查询(如时间范围、标签过滤)
三、市场上最知名的两个方案:MemOS 和 OpenViking
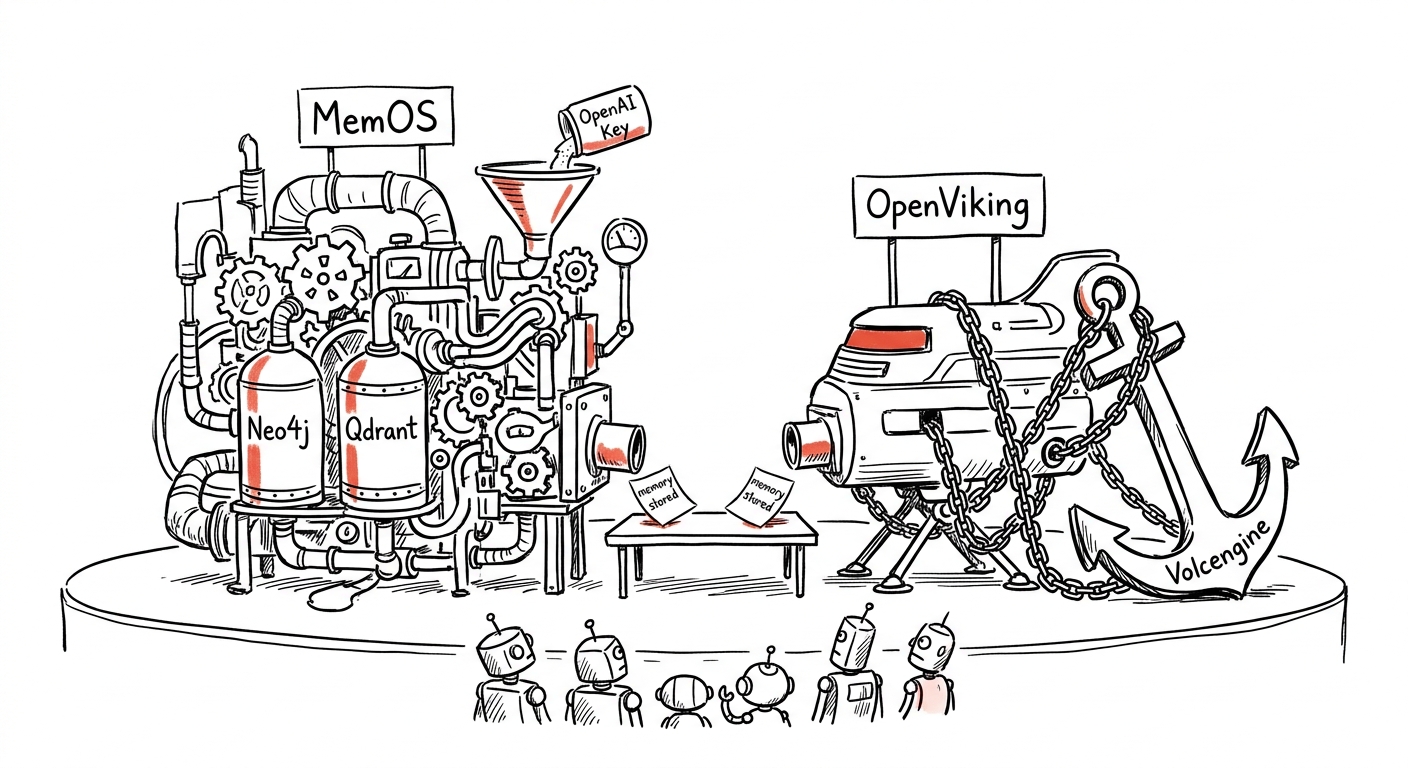
- 三层记忆模型(参数记忆、激活记忆、明文记忆)
- 任务摘要自动化(Next-Scene 预测)
- 技能进化系统(从记忆中提炼可复用技能)
- 数据库:Neo4j(图数据库)+ Qdrant(向量数据库)
- Embedding:需要 OpenAI API Key
- 部署:需要自行搭建或使用云端 beta
- ❌ 部署复杂:需要同时部署数据库(Neo4j + Qdrant)
- ❌ 配置繁琐:需要申请 Key,配置多个环境变量
- ❌ 学习成本高:三层记忆模型需要理解概念
- 文件系统范式(L0/L1/L2 三层加载)
- 目录递归检索(黑盒变白盒)
- 可视化记忆轨迹
- 数据库:VikingDB(字节跳动出品)
- 部署:需要 Volcengine 账号
- ❌ 账号门槛:注册 Volcengine 账号(需要实名认证)
- ❌ 生态绑定:依赖字节跳动的云服务
- ❌ 集成成本:需要开发 OpenClaw 插件
四、灵魂拷问:你愿意花多少时间在"记忆"上?

- ✅ 零门槛启动:不想折腾复杂的注册和配置流程
- ✅ 跨平台统一:笔记本、服务器、多个 Agent 共享同一份记忆
- ✅ 免运维:不想自己部署数据库、管理备份、监控健康
- ✅ 企业级可靠:数据不能丢,性能要稳定
- OpenClaw 原生:本地存储,无法跨平台
- MemOS:部署复杂,需要管理两个数据库
- OpenViking:需要 Volcengine 账号,生态绑定
五、mem9:2 分钟安装的跨平台记忆中枢
- ❌ 注册账号
- ❌ 配置环境变量
- ❌ 部署数据库
- ❌ 管理 Embedding 模型
- API Key 是全局唯一标识符,绑定一个 mem9 记忆空间
- OpenClaw 官方插件支持
- REST API 设计,任何语言都能接入
- 用户通过 REST API(api.mem9.ai)读写记忆
- 无需自行部署任何数据库
- 自动管理存储和检索,用户无需关心底层实现
- ❌ 部署数据库(mem9 云端托管)
- ❌ 管理备份(云端自动处理)
- ❌ 监控健康(GET /healthz 即可检查服务状态)
- ❌ 管理 Embedding 模型(服务端内置)
六、深入对比:技术架构
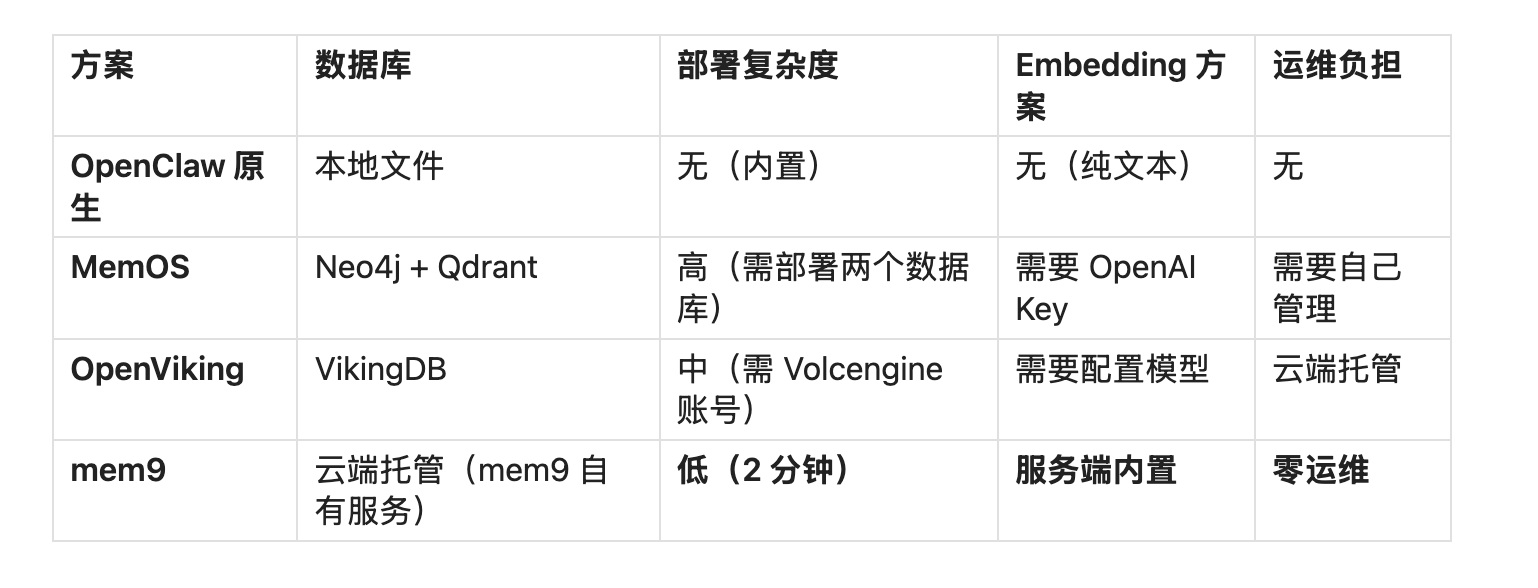
- 云端托管,用户通过 REST API 读写,无需关心底层数据库
- 服务端 Embedding,无需管理 API Key 或部署模型
- 一条命令创建 API Key,即刻可用
- 用户输入 < 5 字符时跳过搜索(如"ok"、"好"不触发)
- 每次最多注入 10 条记忆(MAX_INJECT = 10)
- 每条记忆内容截断到 500 字符(MAX_CONTENT_LEN = 500)
- 无分数门槛:服务端返回的结果全部注入,不做二次筛选
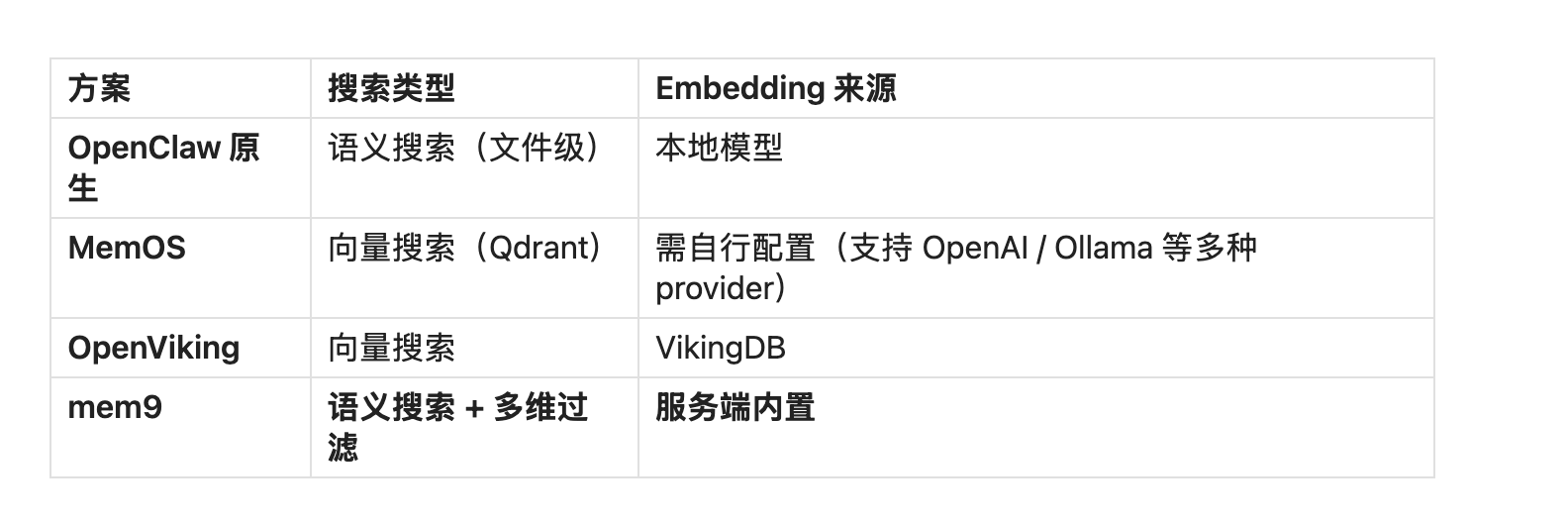
- ✅ 语义搜索(服务端内置 Embedding,无需自行管理模型)
- ✅ 多维过滤(支持 q、tags、source、limit 参数组合)
- ✅ 无需 OpenAI Key(mem9 服务端处理 Embedding)
- ⚠️ 检索质量完全依赖服务端排序,插件端零过滤
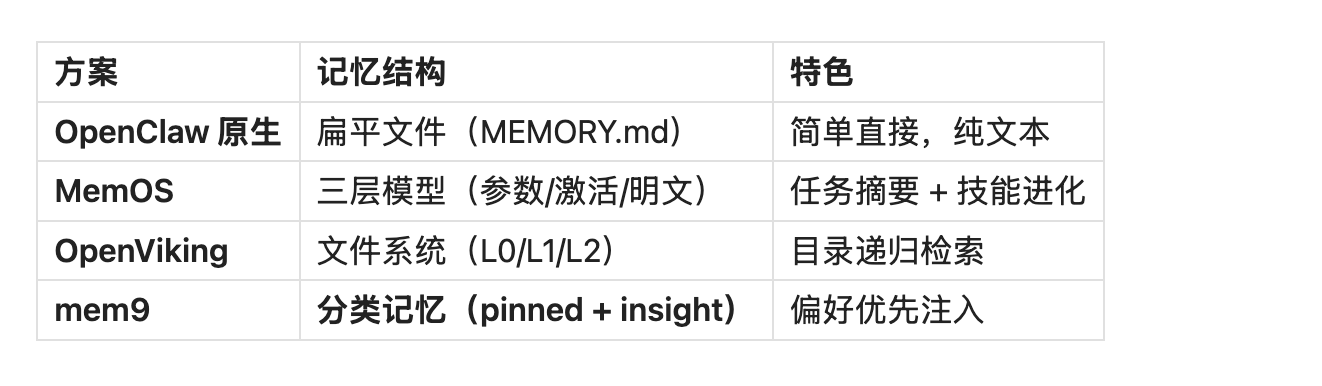
- 服务端自动将记忆标记为 pinned(偏好)或 insight(知识)
- 注入时按分类分组:[Preferences] 排在最前,[Knowledge] 排在其后
- 注入顺序:偏好 → 知识 → 其他,确保 LLM 优先看到用户偏好
- Agent 无需手动指定类型,一切由服务端智能判断
- 每次对话结束后自动触发
- 从对话末尾倒着选消息,总量不超过 200KB(DEFAULT_MAX_INGEST_BYTES),最多 20 条(MAX_INGEST_MESSAGES)
- 自动剥离之前注入的 块,防止记忆“套娃”
- 发送到服务端走 mode: "smart" 智能提取,由服务端 LLM 决定哪些值得记住
- 同一个 API Key,多设备、多框架无缝共享
七、被忽视的杀手锏:LLM 自动语义标签如何让记忆“活”起来

- 开发者需要提前设计标签体系
- 每次写入都要决定“这条记忆该归到哪个标签”
- 标签粒度不一致(有人写“咖啡”,有人写“饮品偏好”)
- 时间一长,标签体系必然混乱
- 对话结束后,插件通过 agent_end 钩子将对话内容发送到服务端
- 服务端 LLM 自动分析对话语义,提取标签(如“咖啡偏好”、“项目架构”、“TypeScript 习惯”)
- 同时进行高频主题统计,识别用户长期关注的核心领域
- 标签和分类信息附着在每条记忆上,成为搜索时的额外维度
- 被标记为 pinned(偏好)的记忆,注入时排在 [Preferences] 区域,LLM 优先看到
- 被标记为 insight(知识)的记忆,注入时排在 [Knowledge] 区域
- 高频出现的标签(比如用户反复提到“TypeScript”),意味着这是核心关注领域,相关记忆的实际召回概率更高

八、启动门槛对比

九、决策树:你该选哪个?
十、总结:mem9 的三大核心优势

- 2 分钟完成部署(创建 API Key → 安装插件 → 配置 openclaw.json)
- 无需注册账号,一条 curl 命令即可生成 API Key
- 免费使用,个人开发者长期零成本
- 云端托管(api.mem9.ai),无需部署任何数据库
- 服务端 Embedding(无需 OpenAI Key)
- 语义搜索 + 多维过滤(tags、source)
十一、参考资源
- 文档:https://docs.openclaw.ai
- GitHub:https://github.com/MemTensor/MemOS
- 论文:arXiv:2507.03724
- GitHub:https://github.com/volcengine/OpenViking
- 文档:https://www.openviking.ai/docs
- GitHub:https://github.com/mem9-ai/mem9
来源:https://x.com/servasyy_ai/status/2035527386842927260
作者:@servasyy_ai(huangserva)
注:本文为按原文图文顺序整理的社区搬运版,便于站内阅读与检索,版权归原作者所有。